Terraform
Terraform, HashiCorp tarafından piyasaya sürülen bir açık kaynak "infrastructure as a code" (IaC) tool'udur. Yani kod yazarak sistemimizde bir takım değişiklikler yapabiliyoruz. Bu değişiklikler kaynak ekleme, çıkartma veya kaynak yönetimi olabilir. Bu şekilde manual yaptığımız işlemleri otomatize etmiş oluyoruz. IaC olarak kullanılan bir çok araç vardır. Aşağıdaki resimde bu anlamda kullanılan araçları görebilirsiniz.
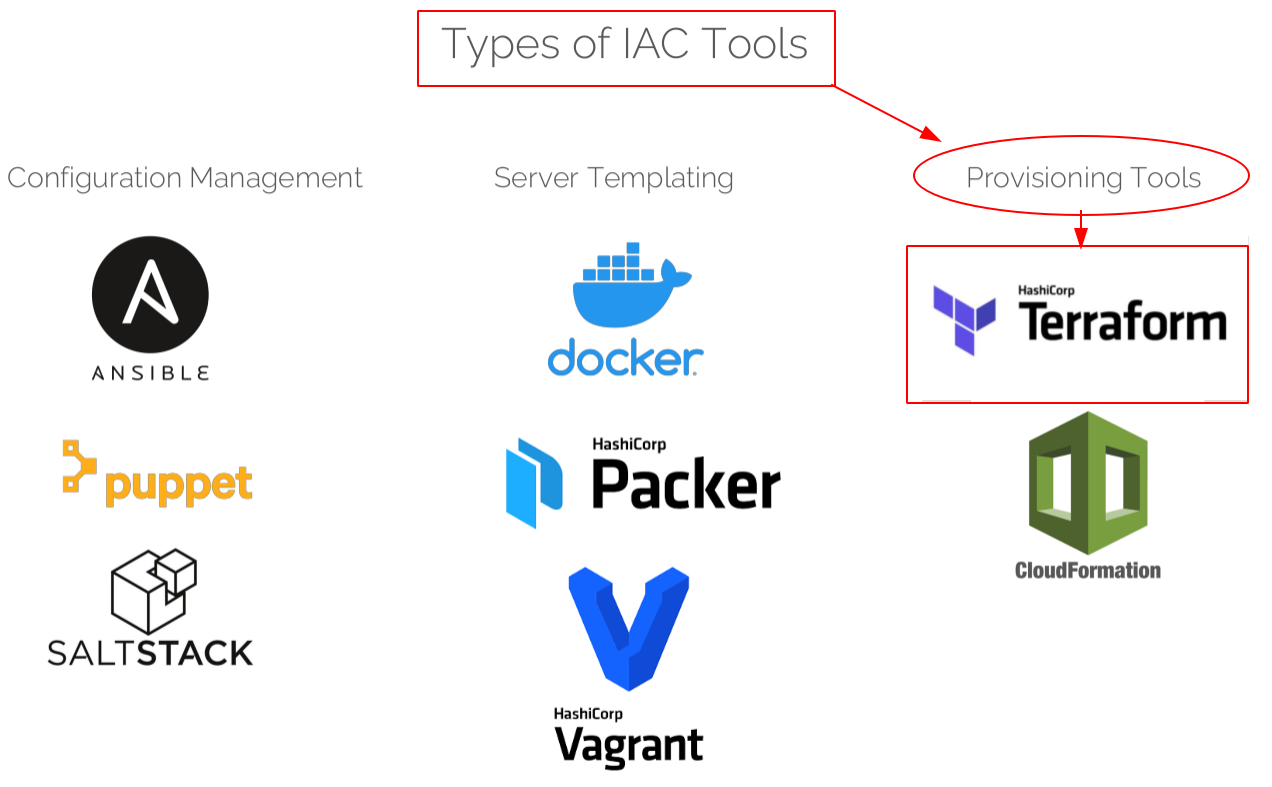
Biz bu ve devamındaki bir kaç yazıda Provisioning Tool’u olan Terraformu konu alacağız. Yukarıdaki resimde görüldüğü gibi benzer işleri yapan tool’lar ayrılmış provisioning anlamında da 2 tool görülüyor. CloudFormation sadece Amazon Web Service Provider’ında kullanılırken Terraform ise platform agnostic’tir. Yani birçok cloud provider’ında ve ayrıca on-premises sistemlerde de kullanılmaktadır.
Terraform Yükleme İşlemi
Bu adımda 2 farklı linux dağıtımında yükleme işlemini gösteriyor olacağım.
Ubuntu için, önce wget ile zip klasörünü indiriyoruz. Zipten çıkarttıktan sonra klasörü /bin altına taşıyoruz ve bitiyor.
wget https://releases.hashicorp.com/terraform/1.0.11/terraform_1.0.11_linux_amd64.zip](https://releases.hashicorp.com/terraform/1.0.11/terraform_1.0.11_linux_amd64.zip
unzip terraform_1.0.11_linux_amd64.zip
sudo mv ./terraform /binAWS içinde Amazon Linux 2 AMI’si için, aşağıdaki komutları uyguluyoruz.
sudo yum update -y
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo
sudo yum -y install terraformİşlem bittikten sonra, aşağıdaki kod ile yüklenip yüklenmediğini kontrol ediniz.
terraform --versionBaşarılı bir kurulum sonrasında aşağıdaki komutu da çalıştırdığınızda otomatik doldurma özelliği sayesinde hızlı kod yazımı mümkün olabiliyor.
terraform -install-autocompleteTerraform platform bağımsız demiştik onun dışında avantaj olarak sayabileceğimiz iki özelliği daha var. Birincisi durum yönetimi, yani state file içerisinde oluşturulan tüm kaynakların son durumunu takip edebiliyoruz. İkincisi ise kullanıcı hatalarına karşı yanlış yapılmasını önlüyor. Hatalı işlem yapıldığında sizi uyarıp bunu mu demek istediniz gibi yardımcı olabiliyor.
Bu yazı dizisinde neler yapacağız biraz bahsedelim. Öncelikle basit kodlar ile AWS tarafında kaynaklar oluşturacağız. Takiben değişkenlerin farklı kullanımlarına bakıp conditionals ve loops kullanımını işleyeceğiz. Daha sonra Data resource tanımlaması, Remote backend ve Provisioner konularına değineceğiz. Son olarak module ve import konularını işleyip bitireceğiz.
Şimdi yavaştan kod yazmaya başlayalım.
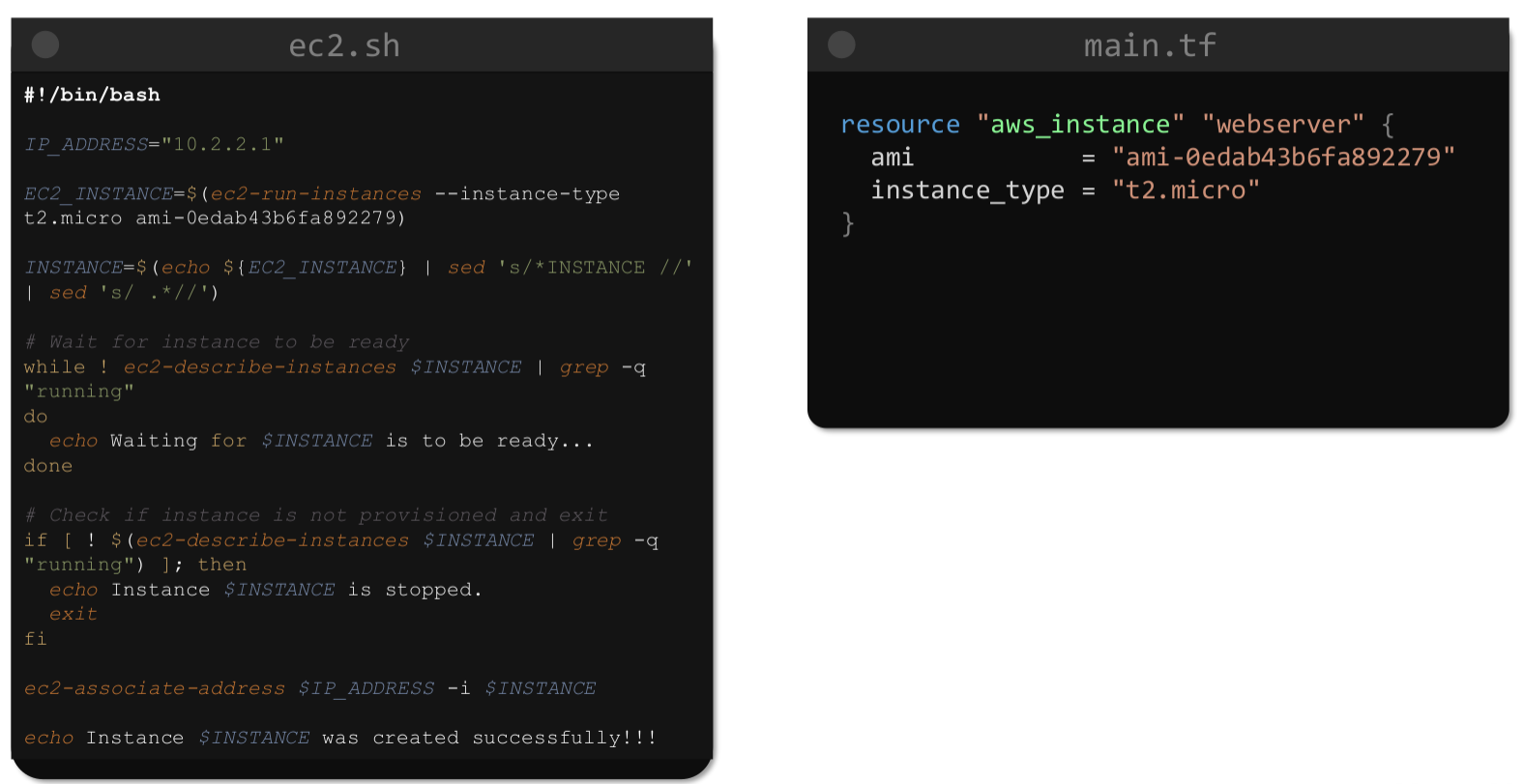
Human readable bir dili ve çok güzel dokümantasyonu var. Aşağıdaki resimden aynı işlemleri yapan shell scripti ve terraform arasındaki farkı görebiliriz.
Öncelikle çalışacağımız provider’ı tanımlamamız gerekiyor. Baştan söyleyelim ezberden ziyade terraform’un resmi sitesi https://registry.terraform.io/ adresini kullanacağız. Provider’ın kaynaklarına erişmek ve işlem yapmak için de authonticate yapmamız gerekiyor. Bunun için 3 farklı yöntem belirteceğim.
- Eğer AWS üzerinden bir Instance ile işlem yapacaksanız IAM Role ile EC2’nuza erişmek istediğiniz kaynaklar için rol tanımlaması yapabilirsiniz.
- Aşağıdaki gibi oluşturacağımız provider bloğunun içerisine gömebiliriz. Uygun bir yöntem değildir. Şifrenin bu şekilde açıkta olmaması gerekir.
provider "aws" { region = "us-east-1" # access_key = "my-access-key" # secret_key = "my-secret-key" ## profile = "my-profile" }
Yeri gelmişken provider bloğundan kısaca bahsedelim. aws ile amazon cloud provider olduğunu belirttik. Region ekleyerek her kaynak oluşturmada bize region sormasının önüne geçtik. profile ile de birden çok aws hesabını yönetiyorsanız farklı profiller tanımlaması yapabiliyoruz.
- AWC CLI kullanıyorsanız CLI configuration yaptığınızda herhangi bir işlem yapmanıza gerek kalmaz. Terraform .aws klasörü içindeki config dosyasıdan bilgileri alır. En uygun yöntem budur.
Terraform kullanırken farklı kod blokları kullanacağız. Örneğin provider, resource, terraform, module, data gibi. Bu araç nasıl çalışıyor önce onu görelim.
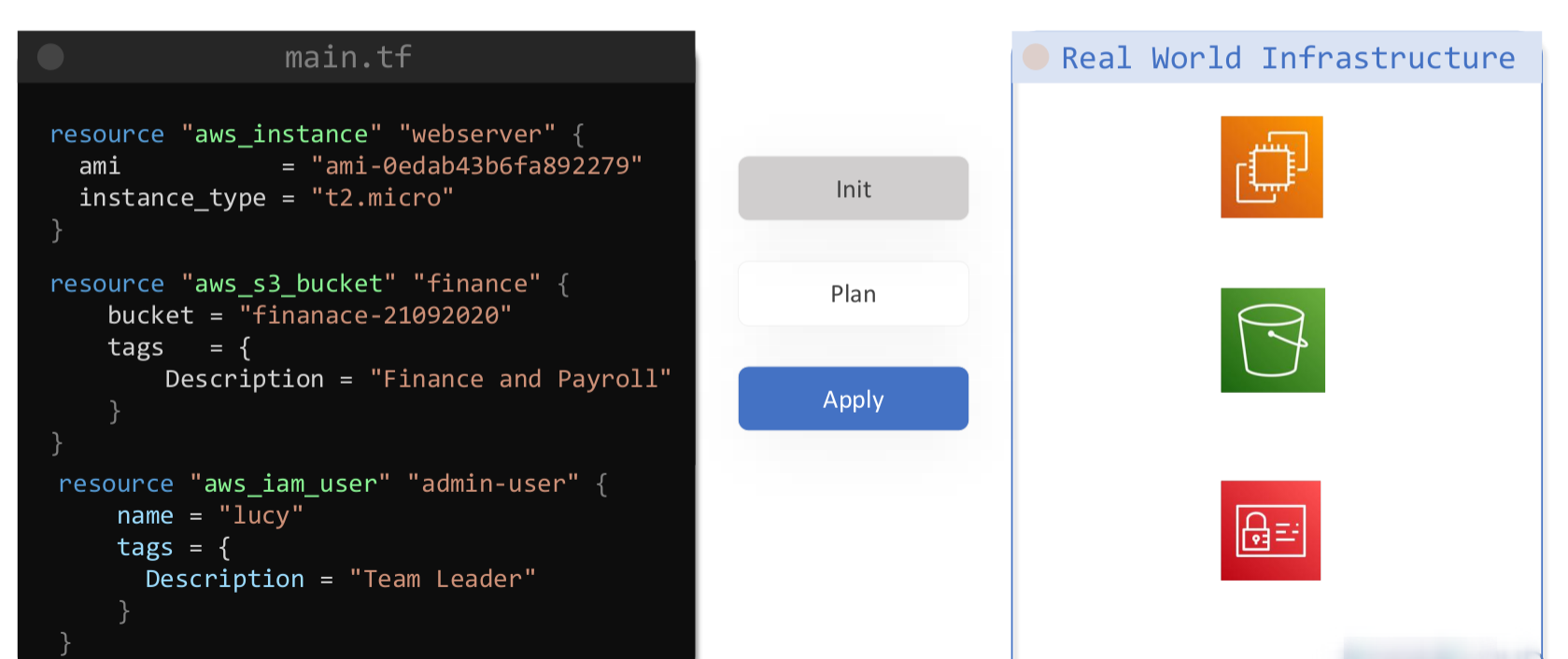
Yukarıdaki resme bakacak olursak sağ taraftaki kaynakları oluşturmak için sol taraftaki .tf uzantılı dosya içerisine kodu yazıyoruz. Bu örnekte 3 adet kaynak oluşturulacak. Bunun için de 3 komutumuz var. Birincisi terraform init . Bu komutu .tf uzantılı dosyanın olduğu klasörde çalıştırıyoruz. Yaptığı işlem, çalışılan klasör içerisinde provider’ın API’ı ile iletişime geçebilmek için provider’ı tespit edip gerekli plug-in ve konfigurasyon dosyaları indirilir. Bu işlem initialize adımı oluyor. Takiben terraform plan komutunu uyguluyoruz. Bu komut zorunlu değildir. Bize ön izleme yapmamızı sağlar yani sen bir sonraki adımda apply komutu çalıştırırsan şu kaynaklar oluşacak şunlar silinecek şunlar değişecek gibi detaylı bir sonuç çıkartacak. Aşağıda işaretler ve anlamlarını görebilirsiniz.
"+" —> oluşturulacak
"-" —> silinecek
"~" —> değiştirilecek
Son adımda ise terraform apply uyguluyoruz burada da artık kaynaklar oluşacak bu komutu takiben tamamlanmadan bizden onay isteyecek “yes” denildiğinde kaynaklar oluşturulacak. Eğer onay için sormasın istersek terraform apply -auto-approve apply komutunu bu şekilde kullanabiliriz. 3 komut gördük yavaş yavaş diğer komutları da kullanımlarıyla göreceğiz.
Öncelikle terraform bloğuna bakalım.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 3.70.0"
}
}
}Terraform bloğu ile plug-in’lerini indireceğimiz provider’ın versiyonunu görebiliyoruz. Ayrıca ileride göreceğimiz backend konusunda backend bloğunu da bu blok içinde yanımlayacağız. terraform init komutu ile buradaki versiyon bilgileri alınacak. Offical provider’lar için zorunlu bir blok değil terraform bu blok olmasa da aws’i tanıyıp plug-in’leri buluyor. Bu blok bilgilerine https://registry.terraform.io/providers/hashicorp/aws/latest adresinden ulaşabilirsiniz.
Provider bloğunu üst kısımda anlatmıştık. Şimdi resource üzerinden kod bloğunu anlamaya çalışalım.
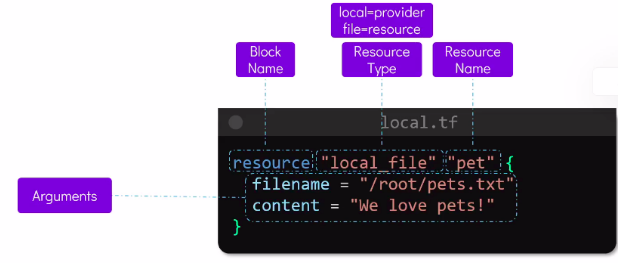
Resme bakacak olursak ilk satırda kod bloğu türü burada resource bloğu, devamında local ile provider ismi, file ile de local provider’ında bir kaynak tipini yazmış oluyoruz. Aynı satırın sonundaki pet o kaynağa verilen isim. Bu değeri istediğimizi verebiliriz daha sonra terraform içinde o kaynağa ulaşmak için local_file.pet şeklinde ulaşacağız. Harf veya alt çizgi ile başlamalıdır ve yalnızca harf, rakam, alt çizgi ve tire içerebilir.
Bir tane de AWS’de bir resource tanımlayalım.
resource "aws_instance" "my_ec2" {
ami = "ami-061ac2e015473fbe2"
instance_type = "t2.micro"
}aws_instance >> aws provider’ında instance tipinde bir kaynak
my_ec2 >> resource’a verdiğimiz isim.
ami ve instance_type >> Ayağa kaldıracağımız makinenin imaj ve tipi
Resource oluştuktan sonra aynı klasörde bazı dosyalar oluşacak. Bunlardan bir tanesi terraform.tfstate dosyası. Apply komutu sonrasında son durum bilgilerinin tutulduğu dosyadır. Oluşan kaynakların tüm detayları bu dosyadadır. İkincisi terraform.tfstate.backup dosyası bu dosya da bir önceki durum bilgilerini tutar. En az 2 apply yapılması lazım bunun oluşması için. Üçüncü dosya .terraform.lock.hcl dosyası. Bu dosya sayesinde provider versiyon kilitlemesi yapılır. Karışıklık çıkmaması için versiyonun değişmemesi gerekir.
Kaynakları İzleme
Şimdi sırayla 3 komut göstereceğim. Bu komutlar oluşturduğumuz kaynaklar hakkında bilgi almak için kullanılacak. Birincisi terraform state list. Bu komut ile hangi kaynaklar oluşmuş özet şeklinde görebiliriz.

İkinci komut ise terraform show. Bu komut ile de her kaynağın önemli özellikleri gayet okunaklı bir çıktı ile gösterilir.
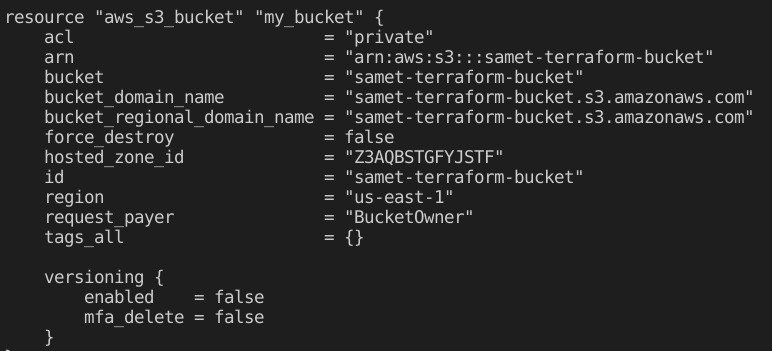
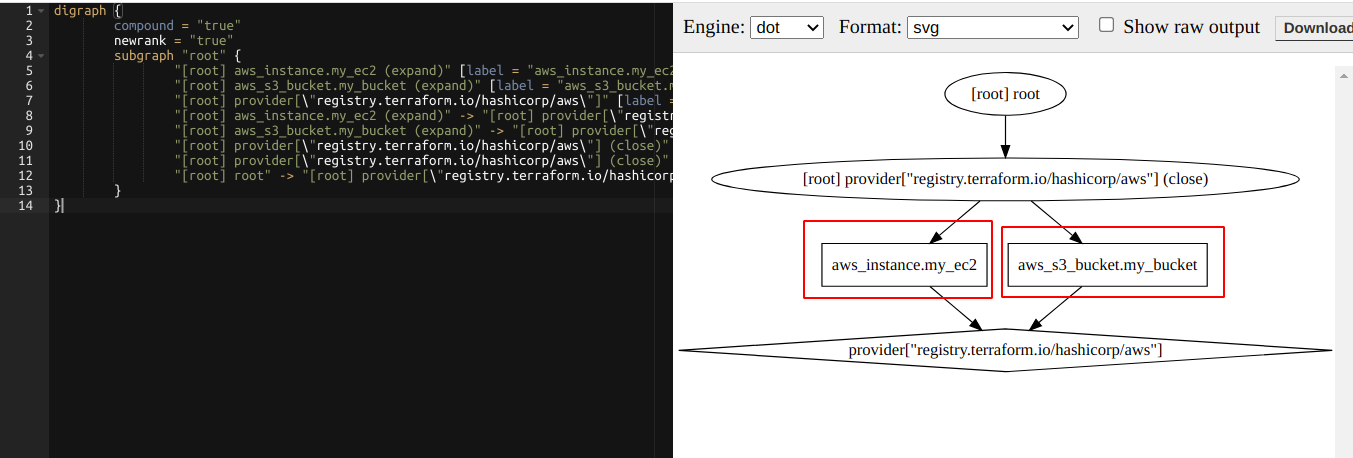
Üçüncü komut terraform graph. Bu komutla oluşan kaynakları görsel olarak izleyebiliyoruz. Önce komutu çalıştırıyoruz. Çıkan sonucu kopyalayıp https://dreampuf.github.io/GraphvizOnline bu sayfayı açtıktan sonra sol kısma kopyalıyoruz.
Hata Kontrolü ve Görünüm Düzeltme
Şimdi de yazım formatında hata var mı diye terraform validate komutunu ve komutun daha düzgün okunaklı olmasın için kullanılan terraform fmt komutunu göstereceğim.
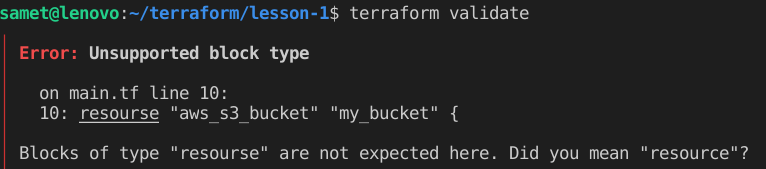
validate sentax hatasını kontrol eder. Yukarıdaki örnekte bilerek resource yerine resourse yazdım. Hatayı gösterdi ve bunu mu demek istediniz şeklinde öneri verdi.
Şimdi de .tf dosyamızın içini biraz bozdum aşağıdaki gibi. ve daha sonra fmt komutunu uyguladım farkına bakalım.
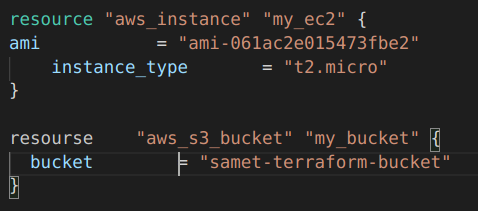
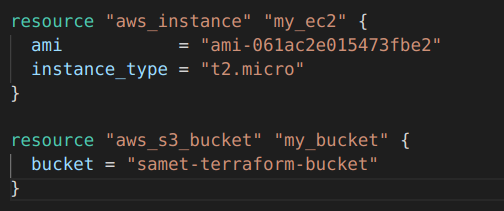
Okunaklı hale getirdi.
Oluşturduğumuz kaynakları temizlemek içinde terraform destroy komutunu uyguluyoruz. Onay istedikten sonra hepsini temizlemiş oluyor.
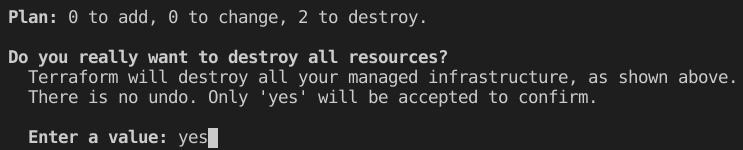
2 resource’um silinecek. Ayrıca spesifik bir resource’u silmek istersek parametre ile destroy komutunu aşağıdaki gibi kullanabiliriz.
terraform destroy -target=aws_s3_bucket.b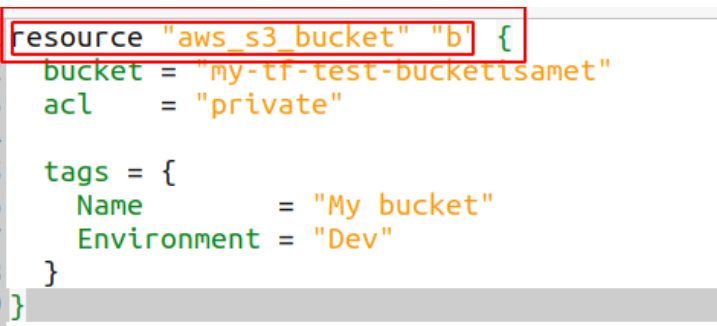
Sıradaki komutumuz terraform console. Bu komut ile interaktif bir komut penceresi açılır. Built-in fonfsiyonları veya herhangi bir değeri görmek için kullanılabilir. Oluşturduğumuz instance’ın public ip sine bakalım.

Output
Bu kısımda output bloğu oluşturmayı göreceğiz. Öncelikle şunu ifade edelim. Terraform çalıştırılan klasördeki tüm .tf uzantılı dosyaları sanki tek file’mış gibi değerlendirir. Biz kodumuz daha okunaklı olsun diye output, variable gibi blokları ayrı file’lara yazarız. Demek istediğim ister ana çalıştığınız resource oluşturduğunuz sayfaya ekleyin ister ayrı file yapın farketmez. Ama best-pratice ayrı file olmasıdır. Kullanım şekli aşağıdaki gibidir.
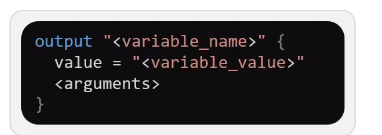
Şimdi oluşturduğumuz ec2’nun public_ip’sini ve s3 bucket’ının ismini çıktı olarak alalım. Bunun 2 yolu var birincisi her apply veya plan komutu ile bu değerleri gösterir.
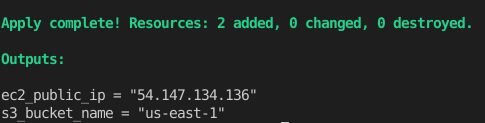
İkincisi ise sadece output ları göstermesi için. terraform output komutunu kullanabiliriz. Ayrıca parametre verip filtreleme yapabiliriz.

Refresh
Daha önce belirttiğimiz gibi terraform state file’ı ile halihazırdaki tüm kaynakların durum bilgileri tutulur. Terraform ile oluşturduğumuz kaynakları konsol üzerinden değiştirirsek eğer buradaki state file’ı içindeki bilgiler ile gerçek durum arasında uyumsuzluklar olur. Bunu gidermek için terraform refresh komutu uyguluyoruz.

Şuan 2 kaynağımız var. Şimdi konsoldan S3 bucket’ını sileceğim ve tekrar aynı komutu çalıştıracağım.

Yine aynı sonucu aldım. Çünkü terraform bunu bilmiyor. Bunun için terraform refresh komutunu çalıştırdıktan sonra tekrar bakalım.
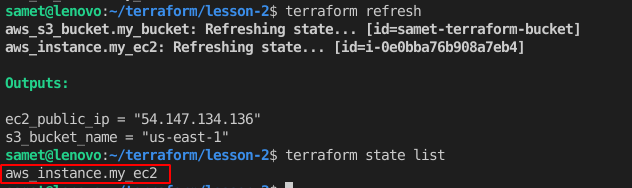
Şimdi burada bir sıkıntı daha var. state file’ı güncellendi ama bizim main.tf aynı kaldı. Yani bir sonraki apply komutu ile sildiğimiz bucket tekrar oluşacak. Bunun için maint.tf de oluşturduğumuz bucket için olan resource bloğunu da kaldırmamız gerekecek.
terraform apply -refresh=false apply komutunu bu parametre ile kullanırsak da şu anlama geliyor. Sen apply yaparken state file ile gerçek durumu kontrol etme yani konsoldan yapılan değişiklikleri dikkate alma. Biraz önceki senaryoyu burada uygularsak. S3 bucket’ı sildim ve apply komutunu tekrar yukarıdaki parametre ile uyguladım.

refresh ile güncelleme yapmadığı için state file da bucket hala var gözüküyor. apply yapıldığında yeni kaynak yokmuş gibi değerlendirecek. Aslında bunu şu şekilde kullanıyoruz. Eğer konsoldan değişiklik yapamadığımıza emin isek vakit kaybı olmasın işlem hızlı gerçekleşsin kontrol yapmasın amacıyla kullanıyoruz.
Variables
Variable'lar neden kullanılır? Başlıca sebepleri şunlardır:
- Gizli olması gereken bilgileri saklamak (AWS credentials gibi).
- Değişme ihtimali olan bilgileri rahat kullanmak (AMI'ler region'a göre değişiklik gösterir).
- Hazır variable'ları tekrar ve kolayca kullanmak.
Farklı şekillerde kullanılabilir.
- Yaygın kullanım variable blokları halinde farklı bir variable.tf file’ı içinde kullanılabilir.
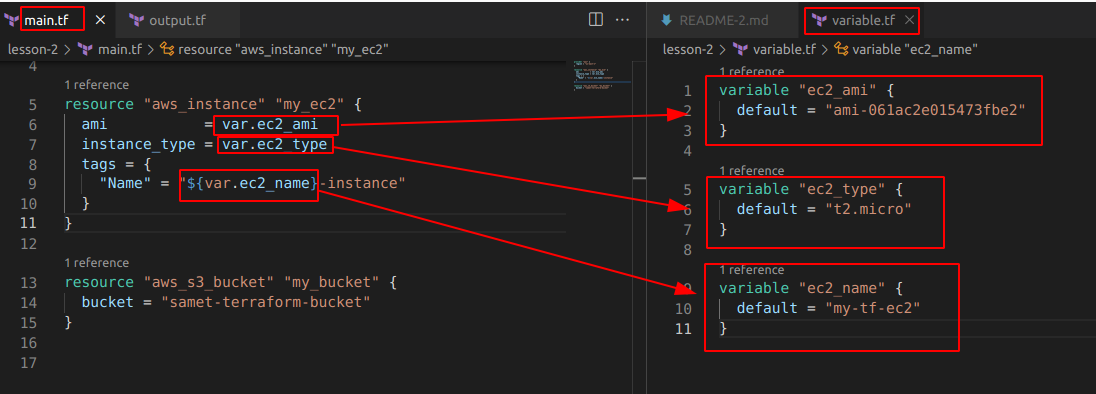
Aynı klasör içinde farklı bir variable.tf içerisinde değişkenler hazırlandı. Aynı main.tf içinde de olabilirdi bu şekilde daha okunaklı olmuş oldu. Bu kullanımda artık herhangi bir değer değiştirmek istenirse ana dosyaya hiç dokunmamıza gerek kalmayacak. Variable içinde optional olan 2 değer daha eklenebilir. Birincisi type, ikincisi description. Description kullanımı best practice’dir. Type olarak, string, number, bool, list, map, object, tuple destekler.
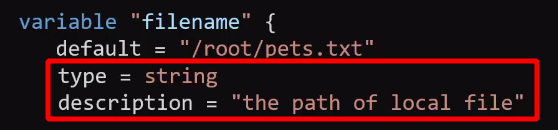

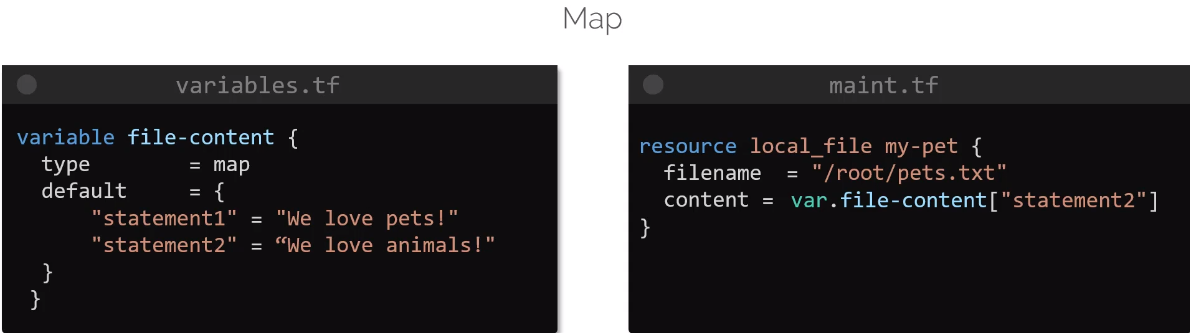
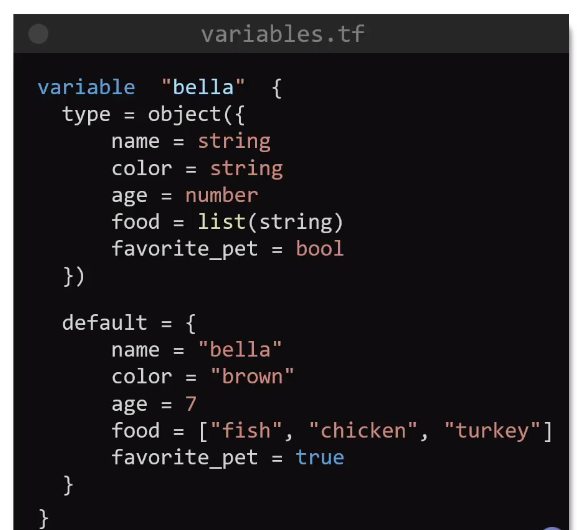
variable bloğu içerisinde default parametresi de aslında optional’dır. default tanımlandıktan sonra içeriği boş bırakılırsa terraform apply yapıldığında interaktif şekilde ilgili değişkenleri girmememiz gerekir.
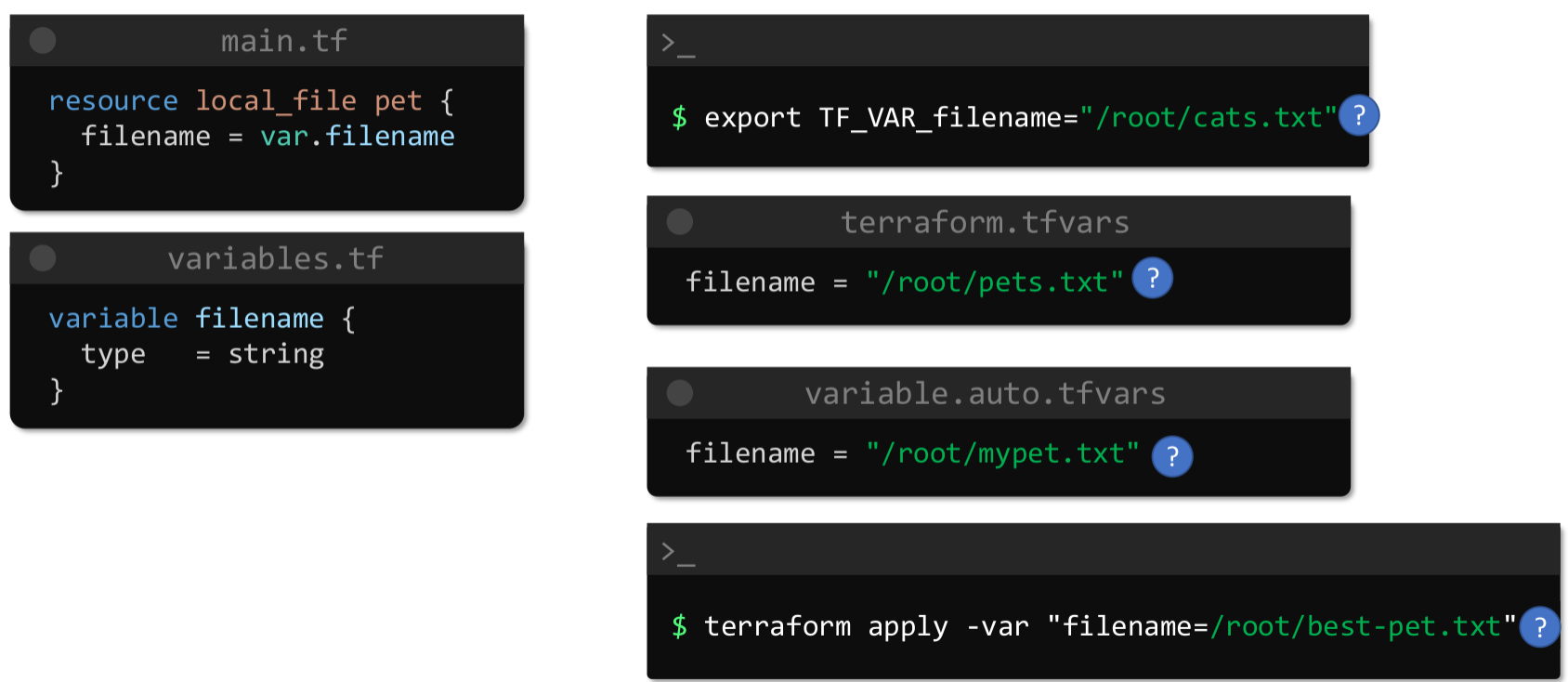
- .tfvars dosyası ile değişken atama. Kişiler kendine özgü değişken dosyası oluşturabilir samet.tfvars gibi. Bu uzantılı dosyalarda öncelik sırası vardır. terraform.tfvars önceliklidir. Ama kendi dosyanızın daha öncelikli olmasını isterseniz samet.auto.tfvars şeklinde auto ilave etmek gerekir.
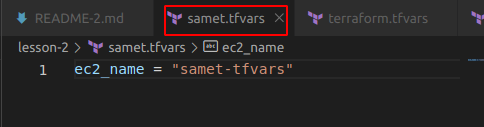
Herhangi bir isimle .tfvars dosyası oluşturduk ve buradakiler geçerli olsun istersek apply veya plan komutunu aşağıdaki gibi çalıştırmamız gerekecek.
terraform apply -var-file="samet.tfvars”
samet.tfvars dosyasını değiştirmeden terraform.tfvars dosyasını da yapalım.
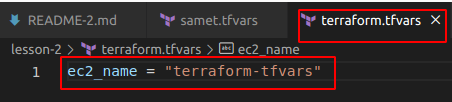

Eğer terraform.tfvars dosyası yaptıysak bunu -var-file=”terraform.tfvars” şeklinde belirtmemize gerek yok terraform apply yaptığımızda değişkeni alır.
- Diğer bir kullanım plan veya apply komutuyla birlikte -var parametresi kullanmak.
terraform plan -var="ec2_name=ec2-degisken-parametre”
- Diğer bir kullanım environment variable ile aşağıdaki gibi tanımlama yapabiliriz.
export TF_VAR_ec2_name= env-den-geldi
Yukarıda 4 farklı değişken tanımlamayı gösterdim. Bunların da kendi aralarında öncelik sırası var;
-varveya-var-fileparametreleri ile apply komutu çalıştırılırsa önce bunu değerlendirir.
- .tfvars dosyası hazırlandı ise sırada bu gelir. Burada da kendi içinde *.auto.tfvars sonra terraform.tfvars en son *.tfvars dosyası değerlendirilir.
- Environment variables
- Default variables
count && for_each
Şu ana dek teker teker kaynak oluşturduk peki bir seferde birden fazla kaynak nasıl oluşturacağız? Burada terraform da count veya for_each ifadelerini kullanacağız. Aynı örneği her iki kullanımla da yapacağım. 3 adet iam user oluşturalım. Önce count ile başlayalım.

Aynı örneği for_each ile yapalım. Fakat burada bir ayrıntı var for_each de variable set veya map tipinde olmalı bu değişikliği variable file ında veya main.tf de yapabiliriz.

Conditionals
Yapı aşağıdaki gibi kurulur.
KOŞUL ? KOŞUL-DOĞRU-İSE ÇALIŞACAK : KOŞUL-YANLIŞ-İSE ÇALIŞACAK
count = var.num_of_buckets > 0 ? 5 : 3
Yukarıdaki örnek üzerinden bakacak olursak var.num_of_bucket değeri 0’dan büyükse count=5 olacak eğer 0 ise count=3 olacak.
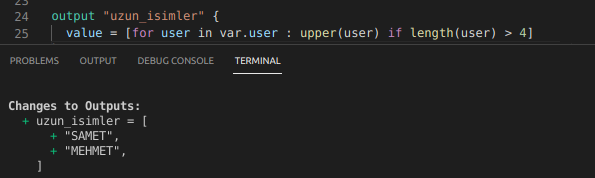
Farklı bir örnek yapalım oluşturduğumuz iam_user’ların isimlerinin uzunlukları 4 karakterden büyükse user isimlerini büyük harfe çevirerek output olarak alalım.
Faydalı VSCode eklenti önerileri:
IntelliJ IDEA Keybindings
HashiCorp Terraform
Terraform doc snippets
Resource Dependencies
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
}
resource "aws_eip" "ip" {
vpc = true
instance = aws_instance.example.id
}Bir resource un diğer resource dan önce oluşturulması gerekebilir.
Implicit and Explicit Dependencies:
Yukarıdaki örnekte implicit bir bağlılık var kaynakların bağımlılığını terraform kendisi çıkartır. Önce instance daha sonra eip oluşturulur.
Örneğin EC2 içindeki bir uygulama S3 bucket ını kullanacaksa bunu explicit bağımlılık olarak depends_on argümanı ile belirtmeliyiz.
resource "aws_s3_bucket" "example" {
bucket = "clarusway-terraform-guide"
acl = "private"
}
resource "aws_instance" "example" {
ami = "ami-2757f631"
instance_type = "t2.micro"
depends_on = [aws_s3_bucket.example]
}Mutable && Immutable Infrastructure
Kaynaklarda değişiklik veya güncelleme yapmanın 2 yolu vardır. Birincisi mutable yani kaynak aynı kalır sadece değişiklik yaparız. İkincisi ise immutable yani yeni istenen özelliklerle yeni bir kaynak oluşturulur ve eskisi destroy edilir. Terraform güncellemeleri immutable olarak gerçekleştirir. Bu işlemi yaparken de önce eski kaynağı destroy eder daha sonra yenisini oluşturur.
Bu yaklaşım kullanıma göre sıkıntılar oluşturabilir. Yani önce yenisi oluşturulsun eskisi daha sonra silinsin isteyebilirsiniz. Bu durumda resource bloğu içine lifecycle bloğu oluşturmak gerekmektedir. Bu blokla ayrıca istenmeden database gibi kaynakların destroy edilmesini de önleyebiliyoruz. Aşağıda örneğini görebilirsiniz.
lifecycle {
create_before_destroy = true
}lifecycle {
prevent_destroy = true
}Data Source
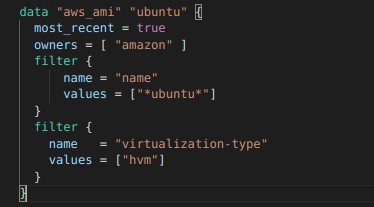
Provider’lar tarafından hazırlanan resource oluştururken kullanılan bloklardır. Offical siteyi incelediğimizde her kaynağın altında onunla ilgili data blokları da yer alır. Amazon tarafından yayınlanan ubuntu imajı ihtiyacımız olduğunu varsayalım. Bu bilgiyi çekmek için data bloklarını kullanabiliyoruz. Aşağıdaki örnekte data bloğunu görebilirsiniz. Dikkat ederseniz filter bloklarıyla kısıtlamalar yapabiliyoruz.
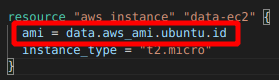
Daha sonra bu bilgiyi ec2 oluştururken aşağıdaki gibi kullanacağız.
Hesabımızda kendi oluşturduğumuz imajımız olsaydı ve bunu kullanmak istese idik bu durumda owner kısmına [”self”] yazmamız gerekecekti.
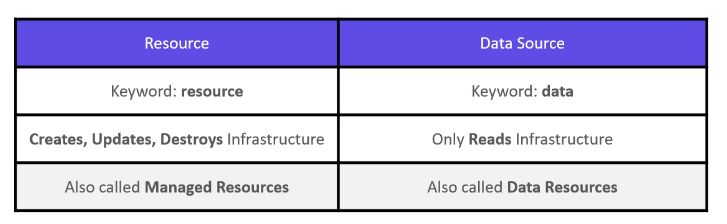
Aşağıda tablodan resource ve data source arasındaki farkı inceleyebilirsiniz.
Remote State
Öncelikle bu özelliğin ne işe yaradığından bahsedelim. Daha önce öğrenmiştik terraform oluşturduğu kaynakları state file’ında tutar. Bir değişiklik yapıldığında state file da değişir. Bir grubunuz var aynı hesap üzerinde çalıştığınızı varsayalım. Birinci kişi 2 adet ec2 3 tane de bucket oluşturdu. Bu kişinin çalıştığı bilgisayarda state file’ında bu kaynaklar oluştu. İkinci kişi de 1 ec2 ve 2 tane de bucket oluşturmak istedi ve kodu çalıştırdı. Sonuç ne olacak? En son çalıştıran kişinin state file’ında da 1 ec2 ve 2 bucket olacak. Toplamda 2 ec2 ve 5 bucket’ımız oldu ama bunlar farklı state file’larda tutuluyor. Bu sıkıntıyı gidermek için yapılmış bir çözümdür remote state.
Burada bir backend tanımlıyoruz. AWS S3 veya terraform Cloud backend örnekleridir. Bu şekilde çalıştığımızda state file’lar S3 gibi uzakta bir yerde muhafaza edilir. Her değişikliği yapan işlemi bitince burdaki state file’a son durum yazılmış olur ve herkes aynı durumu görmüş olur. Bir detay daha var aslında .tf dosyaları da herkeste aynı olması gerekiyor bunun için de github gibi VCS kullanılabilir. Aşağıdaki resim çok güzel özetliyor aslında.
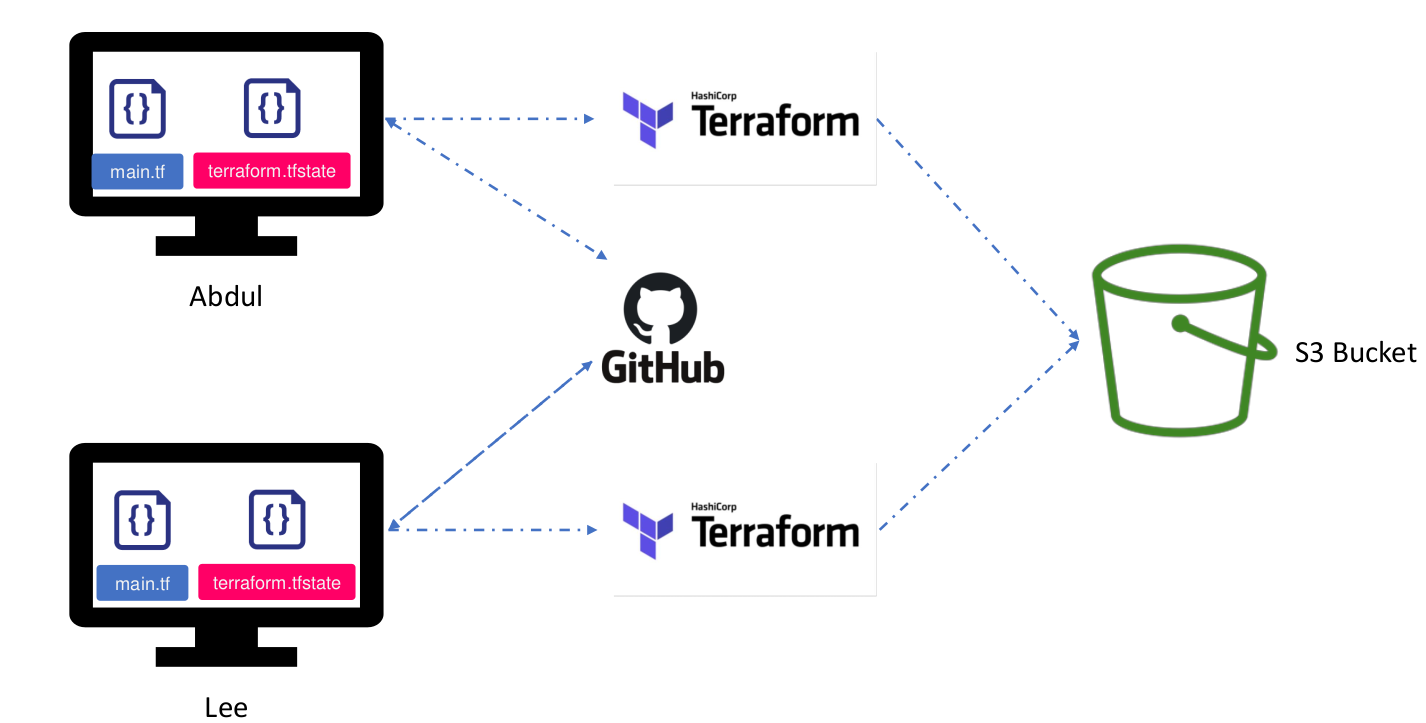
Bu özelliği kullanmak için bir s3 bucket ve bir de dynamodb tablosuna ihtiyacımız var. S3 bucket’ı state file ı tutmak için kullanacağız. Şifreleme ve versiyonlama özelliğini kullanacağız. Dynamodb tablosunu ise lock özelliği için kullanacağız. Eğer aynı anda 2 farklı kişi işlem yapmaya çalışırsa problem çıkacaktır. Bunu önlemek için bir kişi işlem başlattığında diğerlerinin ulaşmasını önlemek için dosya kilitlenir.
Öncelikle farklı bir klasörde backend.tf dosyası oluşturalım. İçeriği aşağıdaki gibi olacak bir adet s3 bucket ve dynamodb tablosu oluşturmuş olacağız.
resource "aws_s3_bucket" "remote-state" {
bucket = "bucket-remote-state"
versioning {
enabled = true
}
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
}
resource "aws_dynamodb_table" "tf-remote-state-lock" {
hash_key = "LockID"
name = "tf-s3-app-lock"
attribute {
name = "LockID"
type = "S"
}
}S3 bucket için versiyonlama özeliğini açtık ve AES256 şifrelemeyi aktif ettik. Dynamodb de ise hash_key = "LockID" özelliği ile aynı anda birden fazla erişim olmaması için kilitleme özelliğini kullandık. Kaynakları oluşturduktan sonra terraform init ve terraform apply komutlarını uygulayalım.
Daha sonra kendi çalıştığımız klasöre dönelim ve main.tf dosyamızda terraform bloğu içerisine aşağıdaki kodu yapıştıralım.
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "3.70.0"
}
}
backend "s3" {
bucket = "tf-remote-s3-bucket-oliver-changehere"
key = "env/dev/tf-remote-backend.tfstate"
region = "us-east-1"
dynamodb_table = "tf-s3-app-lock"
encrypt = true
}
}Bu işlemden sonra terraform init komutu tekrar çalıştırılmalıdır. state file’a baktığınızda boş oluğunu göreceksiniz. Artık State file’lar s3 içerisinde env/dev/ klasörü altında olmuş olacak.
Provisioners
AWS servisi olan EC2 ayağa kaldırırken user data girme özelliği vardı. Daha EC2 ayağa kalkarken script yazarak bazı programların kurulmasını, dosyaların oluşturulmasını sağlayabiliyorduk. Provisioner da aslında bu işi yapıyor kaynak oluşurken aşağıda göstereceğim şekilde bir connection kurup security grubu ayarladıktan sonra bazı işlemleri yaptırabiliyoruz. Bu işlemler kaynakta olacaksa remote-exec provisioner, eğer çalıştığımız klasörde olacaksa da local-exec provisioner diyoruz. ‘ şart vardı tekrar hatırlatayım security grubun ssh portuna izin vermesi ve connection bloğunun hazırlanması. Diğer bir husus provisioner ve connection bloğunun resource bloğu içinde olması gerekiyor.
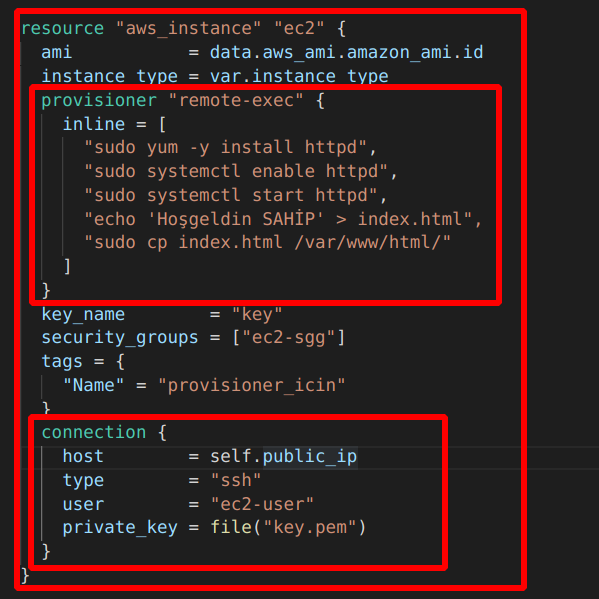
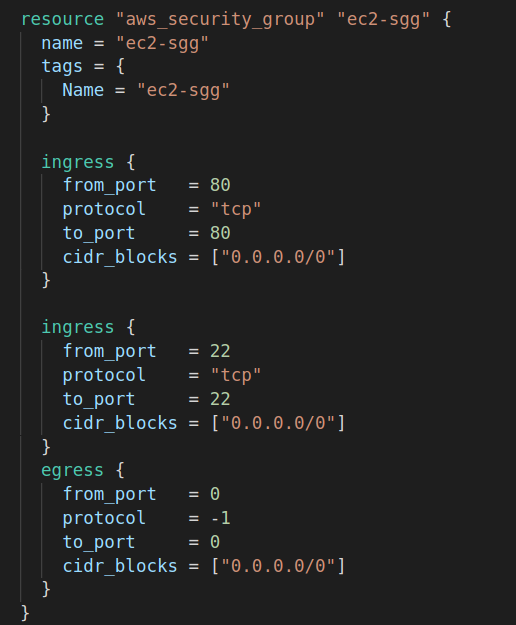

İlk büyük bloğu biliyoruz instance oluşturma bloğu ve sayfanın sonunda bitiyor. İkinci blok remote-exec provisioner bloğu. Birden fazla işlem olduğu için dizi içerisine aralara ”,” koyarak apache web server kurup başlatıyoruz ve HTML klasörü içine bir yazı yazdıran index.html atıyoruz.
Son blok connection bloğu. Dikkat ederseniz ssh bağlantısında kullandığımız parametreleri giriyoruz. “ssh -i key.pem ec2-user@public_ip “ buradaki değerleri girmiş oluyoruz. Security grubu da yandaki gibi ayarladıktan sonra apply dediğimizde public_ip ile istediğimiz sonucu web browser’dan görebiliriz.
Şimdi de local-exec ten basedelim. local-exec provisioner, remote-exec in aksine local terraform binary dosyalarının olduğu makinede işlem yapar. EC2 oluştuktan sonra atanan public ve private ip’yi çalıştığımız makinede bir txt file’ında tutmak istiyoruz. Bu durumda aşağıdaki gibi local exec kullanmamız gerekiyor.

Son olarak provisioner’larda behavior belirtebiliyoruz. Yani destroy edildiğinde arklı komut çalıştırmasını istiyorsak;

veya bir hata olması durumunda görmezden gel demek istersek aşağıdaki gibi behavior girmemiz gerekir. temp klasörü olmadığı için bu hata almayı bekleriz.

Tam burada bir detay daha vermem gerekecek. Eğer on_failure = continue demesek bile Terraform aslında kaynağı oluşturur sadece local-exec’i uygulamaz. Bu durumda terraform bu kaynağı taint yani lekeli kabul eder ve bir sonraki apply da bu kaynağı destroy edip tekrar kurar. Bu özelliği biz kullanmak da isteyebiliriz. Diyelim yeni versiyon kurmak istedik biz remote-exec bloğunu değiştirsek de bir değişiklik görmeyecek. Ama aşağıdaki komutla kaynağı lekeli ilan edip sonraki apply da kaynağı destroy edip daha sonra create etmesini isteyebiliriz.
terraform taint aws_instance.ec2
terraform untaint aws_instance.ec2Bu kadar anlattık ama terraform provisioner kullanmayı son çare olarak kullanın der. Herhangi yetki hatası veya bağlantı hatası durumunda işleminiz gerçekleşmeyecektir. Bunun yerine user data kullanılması daha sağlıklı olacak. AWS deki user data’nın diğer provider’larda da karşılığı mevcuttur.
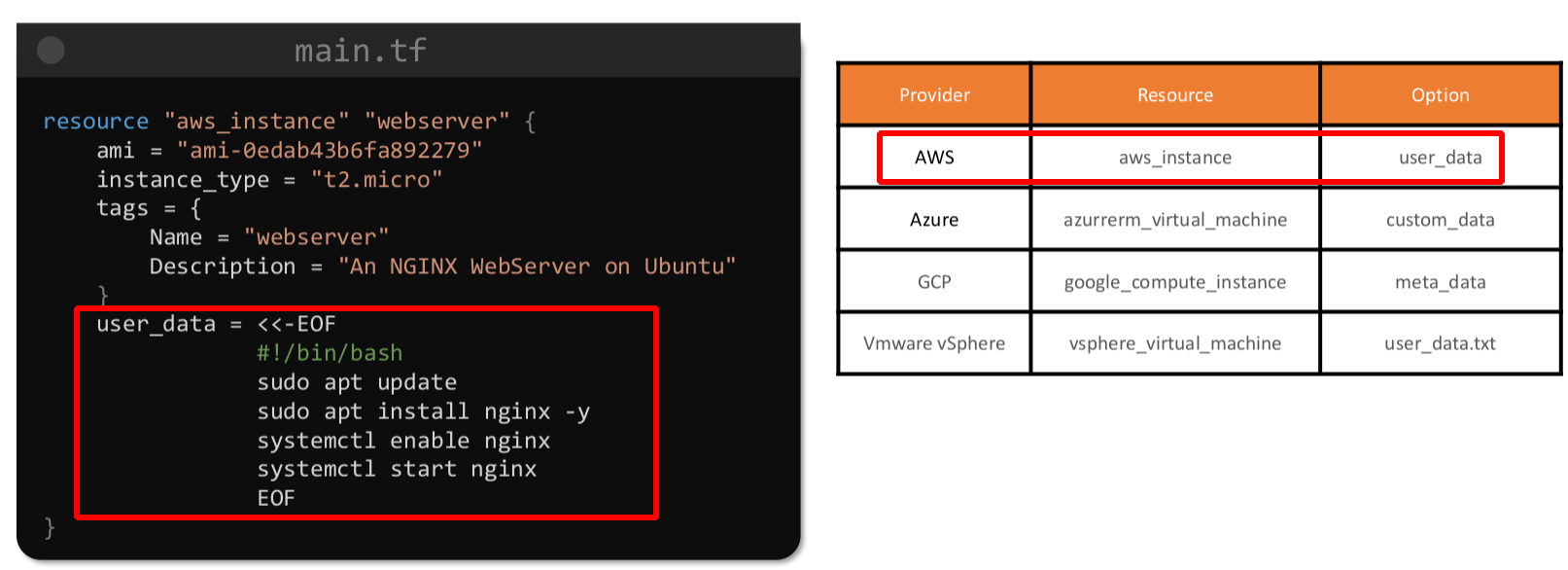
Aslında en sağlıklısı da nginx yüklü bir ami seçip o şekilde instance ayağa kaldırmaktır.
Import
Şimdiye kadar kaynakları terraform kullanarak oluşturduk daha sonra kaldırdık gibi bir takım işlemler yaptık. Ya dışarıda bir kaynağınız daha var bunu da terraform ile kontrol etmek istersek ne yapacağız? Aşağıdaki resimde 3 farklı yöntemle oluşturulmuş resource’ları terraform içine almak istiyoruz. Terraform bu kaynakları import etme şansı veriyor bize.

Öncelikle .tf dosyamıza o kaynağı boş da olsa oluşturmamız gerekiyor. İsterseniz bilinen özeliklerini instance_type, ami vs girebiliriz. Daha sonra da import komutunu çalıştırdığımızda sanki apply yapmış gibi resource terraform tarafından kontrol edilebilir oluyor.
Şimdi AWS konsol’dan bir EC2 oluşturalım ve instance id’sini kopyalayalım. Daha sonra çalıştığımız klasörde bir aws_instance kaynağı oluşturalım, terminalden de import komutumuzu yazalım.
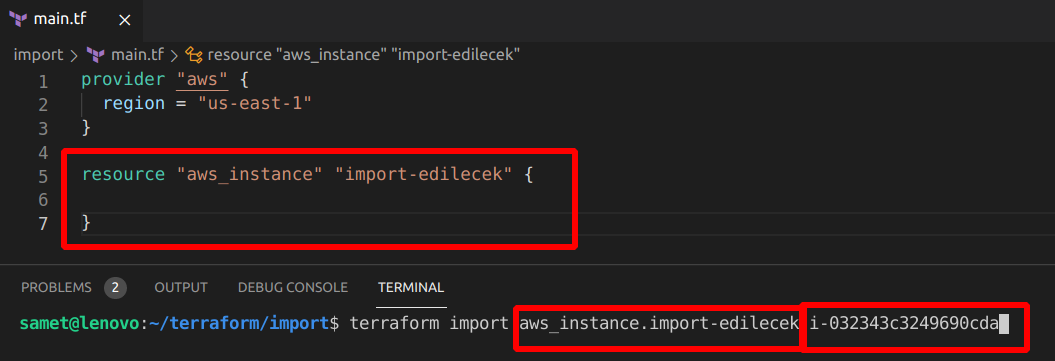
İçeri aldık ama işlem bitmiyor. Kendisi state file oluşturdu ve tüm özellikleri çekildi. Biz bazı bilgileri main.tf’e eklememiz gerekecek. Aşağıdaki gibi bilgileri eklediğimizde sonrasında plan komutunu çalıştırdığımızda no changes yani değişiklik yok almış olacağız. Burada main.tf dosyasını manual olarak hazırlamak zorunda kalıyoruz. Terraform’da bunun farkında ve bu konuda çalıştığını dokümanda belirtmiş.
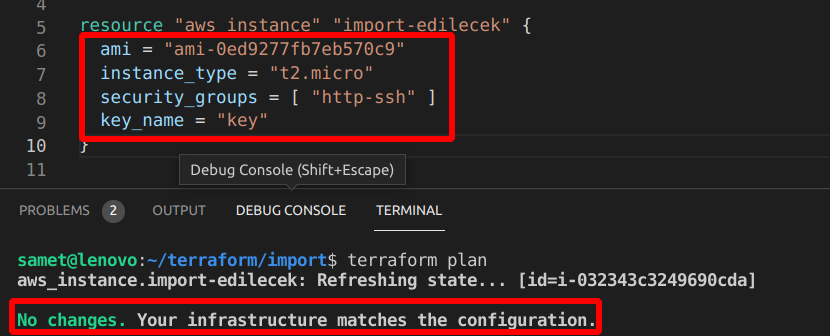
Burada şöyle bir soru gelebilir. EC2’nun dünya kadar özelliği var ben hangilerini girsem yeterli olur? Eğer bilmiyorsak terraform show komutunu çalıştıralım ve çıkan sonucu main.tf e yapıştıralım garanti olmuş olur.
Modules
Bu da son konumuz olmuş olacak. Sürekli farklı birimler için aynı resource’lara ihtiyacımız olacaksa burada module devreye giriyor. Bir templete hazırlıyoruz gibi düşünebiliriz daha sonra hazırladığımız templete’in yolunu göstererek aynı cins yeni kaynakları çok kolay şekilde oluşturabiliyoruz. Temel mantığı anladıysak bir örnek yapalım. Aşağıdaki yapıyı farklı regionlarda kurmamız isterse bunu module ile kolayca yapabiliriz. Bir instance, bir s3 Bucket ve bir de dynamodb table’a ihtiyacımız var.
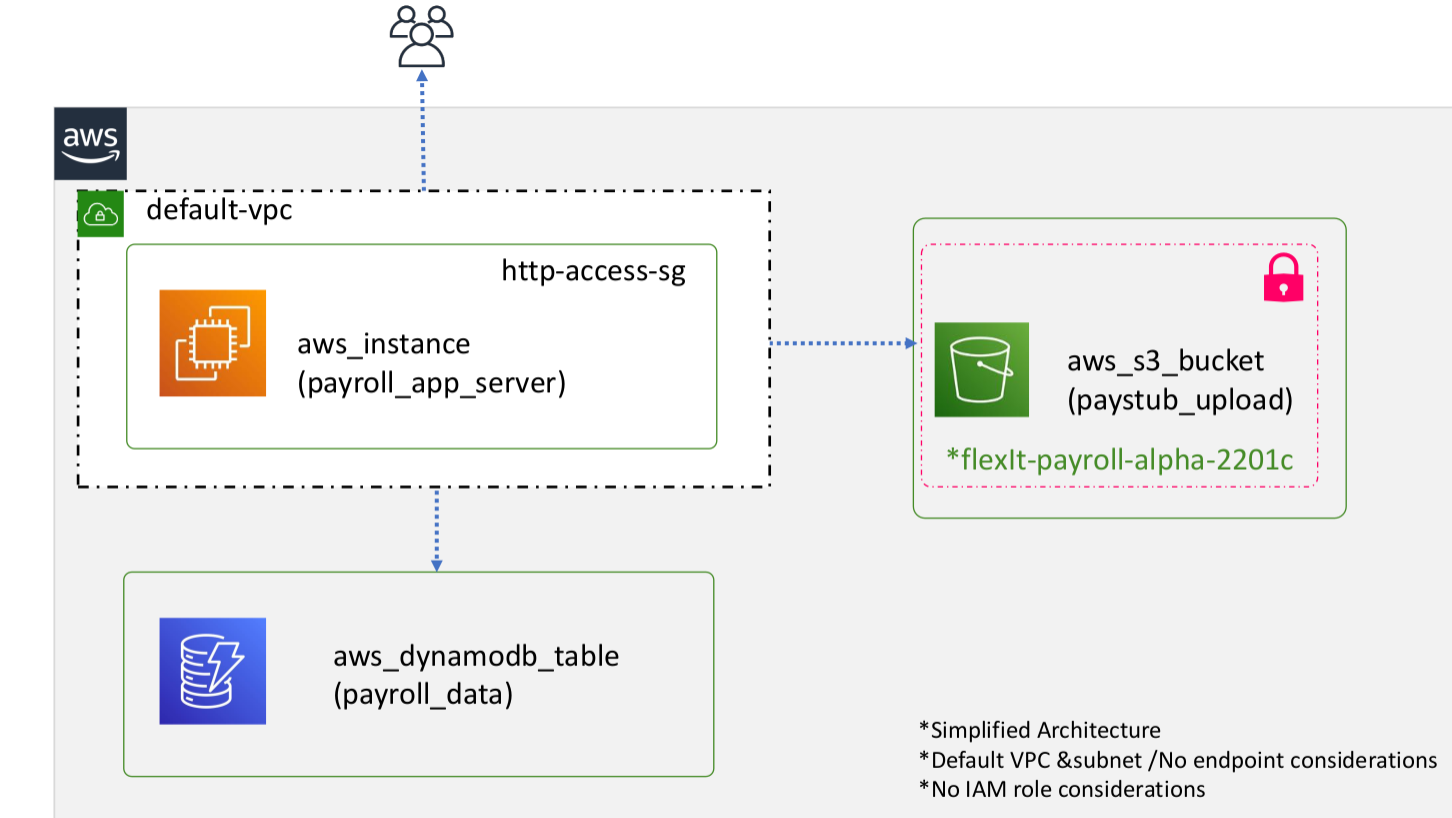
Önce tüm bu resource’ların oluşturulduğu bir modules klasörü içinde .tf dosyalarımızı oluşturalım.
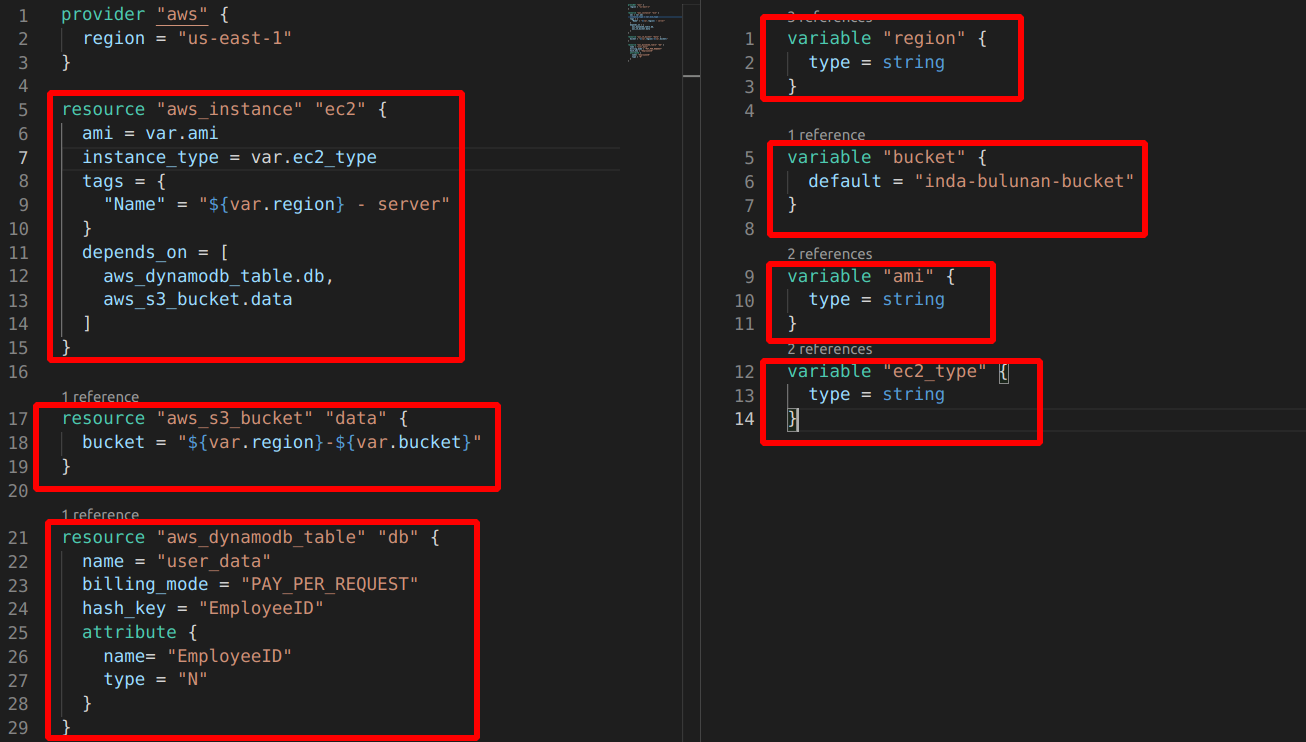
depends_on ile instance’ın S3 bucket ve dynamodb_table’dan sonra oluşturulmasını sağlıyoruz. Diğer kısımlar bu zamana kadar yaptığımız resource oluşturma kısmı. Bu yapıyı bir defa kurduktan sonra aşağıdaki module yapısını kullanarak istediğimiz kadar farklı yerde kullanabileceğiz.
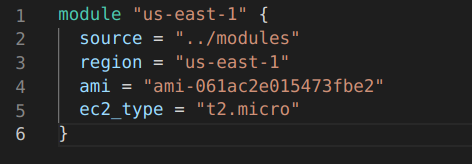
module bloğu oluşturduk. Source olarak bir önceki klasörde bulunan daha önce yukarıda yaptığımız dosyaları gösterdik. variable’ları da tanımladık. Bundan sonra yapacağımız terminaden ilgili klasöre gelip terraform init ve terraform apply komutu vermek.
Çok önemli görmediğim kavram olarak da root child module kavramlarını ayıralım. En son hazırladığımız module blogu alan klasörümüz root module, özellikler aldığımız yani kaynakları oluşturduğumuz kısım ise child module olmuş oluyor. Programlama dillerinde olan package’lere benzetilebilir. Child module de terraform komutları çalıştırılmasına gerek yoktur. Root module de komutlar çalıştığında gerekli kaynak bilgilerini child module’den almış olacak.
Biz bu işlemi local’de hazırladık ve kullandık. Ayrıca offical sitede bulunan daha önce hazırlanan module’leri de kullanabiliriz.
module "security-group" {
source = "terraform-aws-modules/security-group/aws"
version = "4.7.0"
# insert the 3 required variables here
}Yukarıdaki .tf dosyasını kaydettikten sonra terraform get komutunu çalıştırdığımızda aynı klasörde .terraform klasörü altında içeriği görebiliriz.